Data Preprocessing
In the world of machine learning, data preprocessing is the crucial first step before training any model. Raw data is rarely perfect. It can be messy, inconsistent, or incomplete. By preprocessing your data, you ensure that your model learns from clean, accurate, and appropriately formatted information.
In this chapter, we’ll dive into three major aspects of data preprocessing:
- Data Cleaning and Transformation
- Feature Scaling and Encoding
- Handling Missing Data and Outliers
Let’s break down each of these topics step-by-step with detailed explanations and examples.
3.1 Data Cleaning and Transformation
Data cleaning and transformation involve preparing raw data by removing inconsistencies, correcting errors, and ensuring it’s in a suitable format for machine learning models.
Key Steps in Data Cleaning
- Removing Duplicate Data
Duplicate entries can skew model results and lead to overfitting.
Example in Python using pandas:
import pandas as pd
# Sample dataset
data = {
'Name': ['Alice', 'Bob', 'Alice', 'David'],
'Age': [25, 30, 25, 35],
'City': ['New York', 'Los Angeles', 'New York', 'Chicago']
}
df = pd.DataFrame(data)
# Display original DataFrame
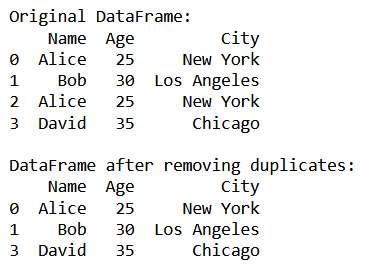
print("Original DataFrame:")
print(df)
# Removing duplicate rows
df_cleaned = df.drop_duplicates()
print("\nDataFrame after removing duplicates:")
print(df_cleaned)
Output:
- Correcting Data Errors
Sometimes, data entries contain typos or formatting issues. These need to be standardized.
Example: Standardizing city names:
df['City'] = df['City'].replace({
'New york': 'New York',
'los angeles': 'Los Angeles'
})- Removing Irrelevant Data
Not all columns are useful for model training. Drop columns that don’t provide value.
Example: Dropping a column:
df = df.drop(columns=['City'])- Fixing Inconsistent Data Formats
Dates, numbers, or strings might be inconsistently formatted.
Example: Converting a date column to datetime format:
df['Date'] = pd.to_datetime(df['Date'])Data Transformation
Data transformation ensures data is in the correct format for machine learning models. This can include:
- Normalization: Adjusting data to a common scale (more on this in the next section).
- Log Transformation: Reducing the impact of extreme values by applying the logarithm.
Example: Log-transforming a feature:
df['Sales'] = df['Sales'].apply(lambda x: np.log(x + 1))3.2 Feature Scaling and Encoding
What is Feature Scaling?
Feature scaling is the process of bringing all numerical features to a common scale. Many machine learning algorithms, such as K-Nearest Neighbors (KNN), Support Vector Machines (SVM), and Gradient Descentbased models, are sensitive to the scale of the data.
Types of Feature Scaling
- Min-Max Scaling (Normalization)Formula:
Formula:

Where:
- μ\mu is the mean of the feature
- σ\sigma is the standard deviation