
Introduction
Machine learning (ML) is a transformative technology that powers everything from voice assistants to advanced data analytics. For beginners, understanding its foundational concepts is crucial to unlocking its full potential. This guide dives into essential machine learning techniques, the training process, and the key elements involved in building ML models.
1. What Are Supervised, Unsupervised, and Reinforcement Learning?
Machine learning can be categorized into three primary types based on how models learn from data:
Supervised Learning
- Definition: In supervised learning, the model learns from labeled datasets, where each input has a corresponding output.
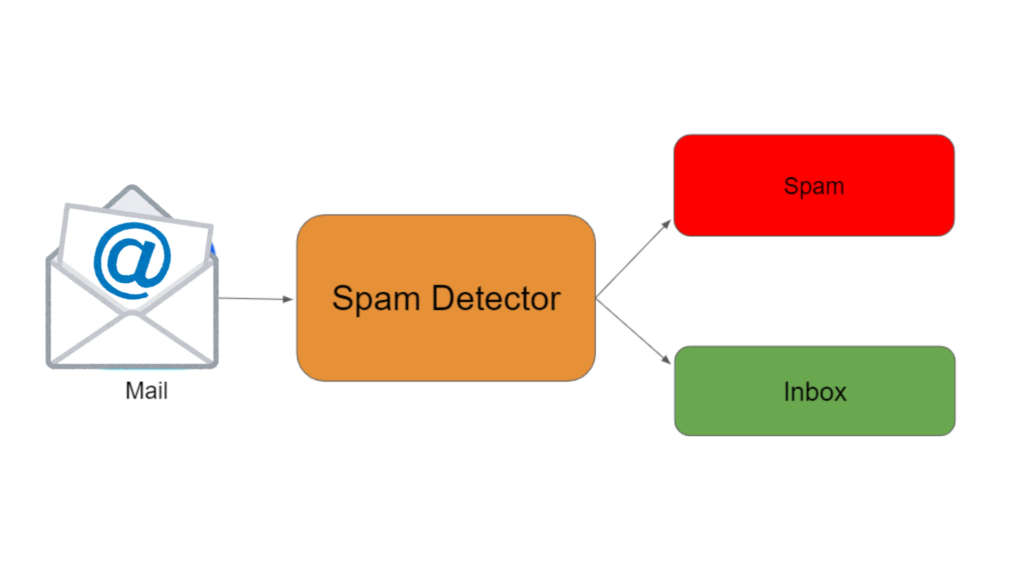
- Key Examples: Image classification, spam email detection, and stock price prediction.
- How It Works: The algorithm maps inputs (features) to outputs (labels) by minimizing errors in its predictions.
- Real-World Application: Predicting whether an email is spam or not, using labeled data for training.
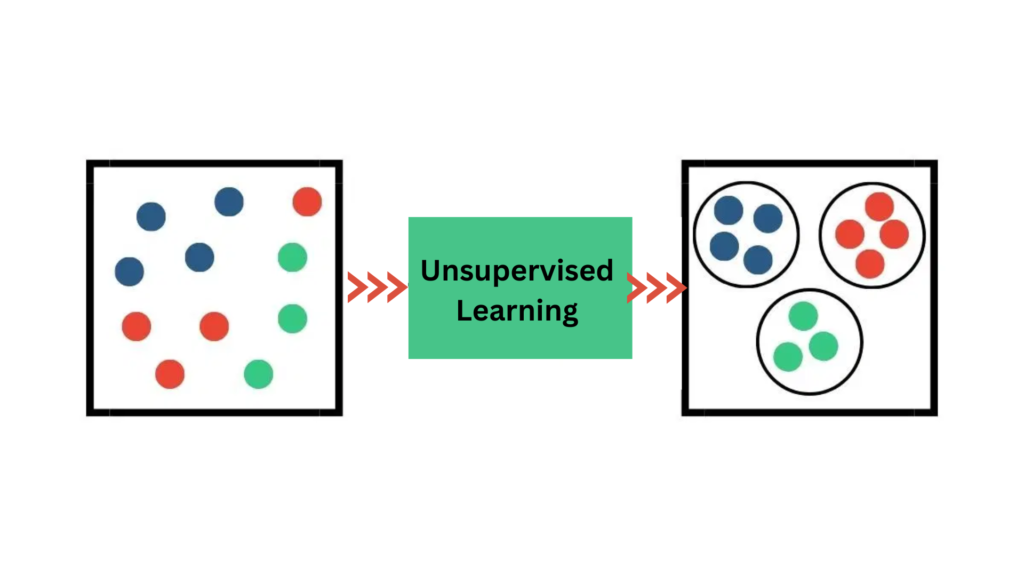
Unsupervised Learning
- Definition: This approach deals with unlabeled data, aiming to discover hidden patterns or structures.
- Key Examples: Clustering, dimensionality reduction, and anomaly detection.
- How It Works: Algorithms like K-Means and PCA group or compress data based on similarities or variance.
- Real-World Application: Customer segmentation in marketing based on purchasing behavior.
Reinforcement Learning
- Definition: In this type, models learn by interacting with an environment and receiving rewards or penalties.
- Key Examples: Robotics, game playing (e.g., AlphaGo), and autonomous vehicles.
- How It Works: Agents take actions to maximize cumulative rewards over time, guided by trial and error.
- Real-World Application: Teaching robots to perform tasks like assembling products.
2. What Is a Machine Learning Model, and How Is It Trained?
A machine learning model is a mathematical representation of a problem-solving process. Training a model involves feeding it data and adjusting its parameters to optimize performance.
Steps in Model Training
- Define the Objective: Specify the task (e.g., classification, regression).
- Choose an Algorithm: Select from options like decision trees, neural networks, or support vector machines.
- Prepare the Data: Collect and preprocess data to ensure quality.
- Train the Model: Feed the data into the algorithm, allowing it to adjust based on error minimization.
- Evaluate and Optimize: Measure performance using metrics like accuracy or precision, and tweak hyperparameters.
Real-Life Example
Training a spam detection model involves providing thousands of emails, labeled as “spam” or “not spam,” allowing the algorithm to learn distinguishing patterns.
3. What Is the Difference Between Training, Testing, and Validation Datasets?
Datasets are divided into subsets to ensure robust model performance:
Training Dataset
- Purpose: Used to train the model by adjusting parameters to minimize prediction errors.
- Size: Usually the largest portion (60-80% of the data).
Validation Dataset
- Purpose: Helps tune hyperparameters and avoid overfitting.
- Size: Typically 10-20% of the data.
Testing Dataset
- Purpose: Evaluates the model’s final performance on unseen data.
- Size: Usually 10-20% of the data.
Key Difference
- Training teaches the model.
- Validation fine-tunes it.
- Testing measures how well it generalizes to new inputs.
4. What Are Features and Labels in Machine Learning?
Features
- Definition: Independent variables or attributes used to make predictions.
- Examples: In a housing price prediction model, features could include the number of bedrooms, square footage, and location.
Labels
- Definition: The dependent variable or target the model aims to predict.
- Examples: For the same housing model, the label would be the house price.
Feature Engineering
The process of selecting, transforming, or creating new features to improve model performance is known as feature engineering.
Importance
- High-quality features lead to better predictions.
- Poor feature selection can result in biased or inaccurate models.
5. How Does a Machine Learning Algorithm “Learn”?
Learning in ML involves finding patterns or relationships within the data to make accurate predictions. This process varies by algorithm but generally includes:
1. Initialization
- The model starts with random weights or parameters.
2. Forward Propagation
- The input data is processed, and predictions are generated.
3. Error Calculation
- A loss function calculates the difference between predicted and actual values.
4. Backpropagation
- The error is propagated backward, updating the model’s parameters to minimize it.
5. Iterative Improvement
- The process repeats across multiple iterations (epochs) until the model converges to a low error rate.
Example: Gradient Descent
This optimization algorithm adjusts parameters by moving in the direction of the steepest decrease in error.
Outcome
Through this iterative process, the algorithm “learns” to generalize from the training data to make predictions on unseen data.
Some Basics Questions On Machine Learning and Short Answer
1. What Is Overfitting in Machine Learning?
Overfitting occurs when a model performs exceptionally well on training data but poorly on unseen data. This happens when the model learns noise or irrelevant details instead of the actual patterns.
2. Can Machine Learning Work Without Big Data?
Yes, smaller datasets can be used effectively, especially for algorithms like decision trees or linear regression. However, more data often leads to better model performance.
3. What Are Popular ML Libraries for Beginners?
Libraries like Scikit-learn, TensorFlow, and PyTorch offer user-friendly tools to build and train models.
4. How Do You Choose the Right Algorithm?
It depends on the problem type, data size, and computational resources. For example, decision trees work well for interpretable models, while neural networks are better for complex tasks like image recognition.
5. Why Is Data Preprocessing Important?
Preprocessing cleans and formats data, addressing issues like missing values, outliers, or inconsistent units, which can negatively impact model accuracy.
6. What Is Transfer Learning?
Transfer learning leverages a pre-trained model on a similar task, reducing the need for extensive data and training time.
Conclusion
Machine learning offers endless possibilities, but understanding its foundational concepts is essential to harness its power. From supervised to reinforcement learning, the journey involves crafting models, selecting features, and iterative training. As you embark on your ML learning path, remember that practice, experimentation, and curiosity are key to mastering this exciting field.